Data Science с R в Microsoft Azure (часть 2)
R, один из популярнейших языков программирования среди data scientist'ов, получает все большую и большую поддержку как среди opensource-сообщества, так и среди частных компаний, которые традиционно являлись разработчиками проприетарных продуктов. Среди таких компаний – Microsoft, чья интенсивно увеличивающая поддержка языка R в своих продуктах/сервисах, привлекла к себе и мое внимание.
Одним из «локомотивов» интеграции R с продуктами Майкрософт является облачная платформа Microsoft Azure. Кроме того, появился отличный повод повнимательнее взглянуть на связку R + Azure – это проходящий в эти выходные (21-22 мая) хакатон по машинному обучению, организованный Microsoft [1].
В прошлой части я озвучил 3 тезиса:
- 1. Время на хакатоне крайне ценный ресурс.
- 2. Правильная организация командной работы дает вам большое преимущество.
- 3. Azure ML – не инструмент прототипирования, для прототипирования стоит использовать R/Python.
Azure Machine Learning
Azure Machine Learning (Azure ML) – облачный сервис для выполнения задач, связанных с машинным обучением. Почти наверняка Azure ML будет центральным сервисом, которым вы будете пользоваться, в случае, если захотите обучить модель, в облаке Azure.
Подробный рассказ про Azure ML не входит в цели данного поста, в тем более, что о сервисе уже достаточно написано: Azure ML для data scientist’ов [3], best practices обучения модели в Azure ML [4]. Сконцентрируемся на следующей задаче: организация командной работы с максимально безболезненным переносом R-скриптов с локального компьютера в Azure ML Studio.

1. Начальные требования
Для задуманного понадобятся следующие бесплатные программные продукты:
- Для консерваторов: R (runtime), R Studio (IDE).
- Для демократов: R (runtime), Microsoft R Open (runtime), Visual Studio Community 2015 (IDE), R Tools для Visual Studio (IDE extension).
Для работы в Azure понадобится активная подписка Microsoft Azure.
2. Начало работы: collaboration everything
Один workspace в Azure ML на всех
Создаем один(!) на всю команду workspace в Azure ML и расшариваем его между всеми участниками команды.
Один репозиторий кода на всех
Создаем один облачный Team Project (TFS в Azure) / репозиторий в GitHub и также расшариваем его на всю команду.
Думаю, очевидно, что теперь часть команды, работающая над одной задачей хакатона, делает коммиты в один репозиторий, коммитит фичи в бранчи, бранчи мержит в мастер – в общем идет нормальная командная работа над кодом.
Один набор начальных данных на всех
Зайдите в Azure ML Studio (web IDE), перейдите на вкладку «Datasets» и загрузите набор изначальных данных в облако. Сгенерируйте код доступа (Data Access Code) и разошлите его команде.
Так выглядит интерфейс загрузки данных в Azure ML Studio:

Листинг 1. R-скрипт для загрузки данных
library("AzureML")
ws <- workspace(
id = "<workspace_id>",
auth = "<auth_token>",
api_endpoint = "https://europewest.studioapi.azureml.net")
data.raw <- download.datasets(
dataset = ws,
name = "ML-Hackathon-2016-dataset")
3. Jupyter Notebook: выполнение R-скриптов в облаке и визуализация результатов
После того, как дата, код и проект в Azure ML оказались в общем для всей команды доступе, пора научиться делиться визуальными результатами исследования. Традиционно для этой задачи data science community любит использовать Jupyter Notebook – клиент-серверное веб-приложение, позволяющее разработчику объединить в рамках единого документа: код (R, Python), результаты его выполнения (в т.ч. графики) и rich-text-пояснения к нему.
Создадим в Azure ML документы Jupyter Notebook:
- 1. Создаем отдельный документ Jupyter Notebook на участника.
-
2. Заливаем единый расшаренный начальный набор данных из Azure ML (код из листинга 1). Код работает и при запуске из локальной R Studio, поэтому ничего нового для Jupyter Notebook писать не надо – просто берем и копируем код из R Studio.
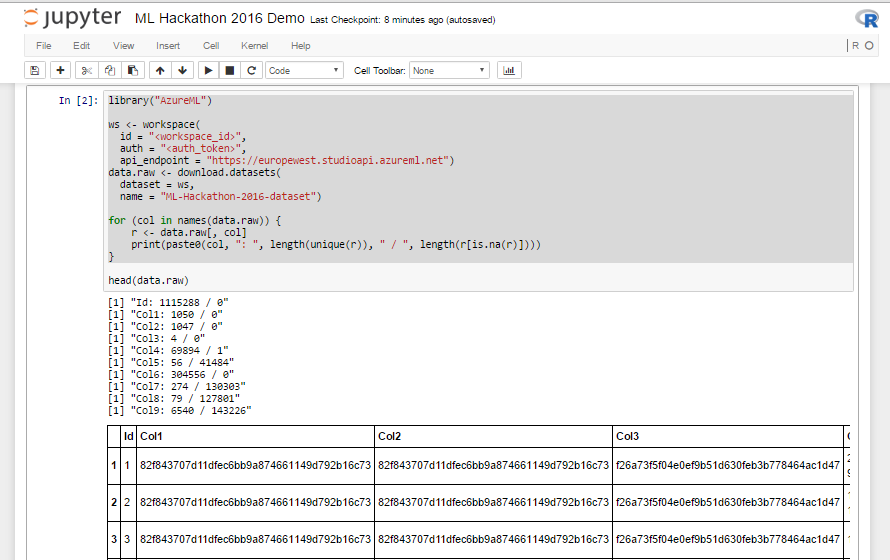
-
3. Делимся ссылкой на документ Jupyter Notebook с командой,
кидаемся каобсуждаем, дополняем непосредственно в Jupyter Notebook.

В результате на каждую задачу хакатона должны получиться несколько Jupyter Notebook документов:
- содержащих R-скрипты и результаты их выполнения;
- над которыми пофантазировала-подумала вся команда;
- с полным flow: от загрузки данных до результата применения алгоритма машинного обучения.
Вот так это выглядит у меня:

4. Prototype to Production
На этом этапе у нас есть несколько исследований, по которым получен приемлемый результат и соответствующие этим исследованиям:
- в GitHub/Team Project: бранчи с R-скриптами;
- в Jupyter Notebook: несколько документом с обсужденными в команде результатами того, что получилось.
Следующий шаг – создание в Azure ML Studio экспериментов (вкладка «Experiments») – далее AzureML-экспериментов.
На этом этапе необходимо придерживаться следующих best practices при переносе R-кода в AzureML-эксперимент:
Модули:
- 1. По возможности не используйте встроенный модуль «Execute R script» как контейнер для выполнения R кода: у него нет поддержки версионности (сделанные внутри модуля изменения кода нельзя откатить), модуль в совокупности с R кодом не может быть переиспользован в рамках другого эксперимента.
- 2. Используйте возможность загружать пользовательские R-пакеты (Custom R Module) в Azure ML (о процессе загрузки ниже). Custom R Module имеют уникальное имя, описание модуля, модуль можно переиспользовать в рамках различных AzureML-экспериментов.
R-скрипты:
- 3. Организуйте R-скрипты внутри R-модулей как набор функций с одной точкой входа.
- 4. Переносите в Azure ML в виде R-кода только тот функционал, который невозможно/сложно воспроизвести с помощью встроенных модулей Azure ML Studio.
- 5. R-код в модулях выполняется со следующими ограничениями: отсутствует доступ к persistence-хранилищу и сетевому соединению.
В соответствии с правилами выше перенесем наш R-код в AzureML-эксперимент. Для нам необходим zip-архив, состоящий из 2-ух файлов:
-
1. .R-файл, содержащий код, который мы собираемся перенести в облако.
Пример с поиском/фильтрацией выбросов в данных:
PreprocessingData <- function(dataset1, dataset2, swap = F, color = "red") { # do something # ... # detecting outliners range <- GetOutlinersRange(dataset1$TransAmount) ds <- dataset1[dataset1$TransAmount >= range[["Lower"]] & dataset1$TransAmount < range[["Upper"]], ] return(ds) } # outlines detection for normal distributed values GetOutlinersRange <- function(values, na.rm = F) { # interquartile range: IQ = Q3 - Q1 Q1 = quantile(values, probs = c(0.25), na.rm = na.rm) Q3 = quantile(values, probs = c(0.75), na.rm = na.rm) IQ = Q3 - Q1 # outliners interval: [Q1 - 1.5IQR, Q3 + 1.5IQR] range <- c(Q1 - 1.5*IQ, Q3 + 1.5*IQ) names(range) <- c("Lower", "Upper") return(range) } -
2. Xml-файл, содержащий определение/метаданные нашей R-функции.
Пример (раздел Arguments просто для «широты» примера):
<Module name="Preprocessing dataset"> <Owner>Dmitry Petukhov</Owner> <Description>Preprocessing dataset for ML Hackathon Demo.</Description> <!-- Specify the base language, script file and R function to use for this module. --> <Language name="R" entryPoint="PreprocessingData " sourceFile="PreprocessingData.R" /> <!-- Define module input and output ports --> <Ports> <Input id="dataset1" name="Dataset 1" type="DataTable"> <Description>Transactions Log</Description> </Input> <Input id="dataset2" name="Dataset 2" type="DataTable"> <Description>MCC List</Description> </Input> <Output id="dataset" name="Dataset" type="DataTable"> <Description>Processed dataset</Description> </Output> <Output id="deviceOutput" name="View Port" type="Visualization"> <Description>View the R console graphics device output.</Description> </Output> </Ports> <!-- Define module parameters --> <Arguments> <Arg id="swap" name="Swap" type="bool" > <Description>Swap input datasets.</Description> </Arg> <Arg id="color" name="Color" type="DropDown"> <Properties default="red"> <Item id="red" name="Red Value"/> <Item id="green" name="Green Value"/> <Item id="blue" name="Blue Value"/> </Properties> <Description>Select a color.</Description> </Arg> </Arguments> </Module>
Загрузим полученный архив через Azure ML Studio. И выполним эксперимент, убедившись, что скрипт отработал и мы обучили модель.

Теперь можно улучшить существующий модуль, загрузить новый, устроить соревнование между ними – в общем пользоваться благами инкапсуляции и модульной структуры.
Заключение
По моему мнению R экстремально эффективен в прототипировании, и от этого он прекрасно себя зарекомендовал с хакатонах и в исследованиях. В то же время между прототипом и продуктом существует труднопреодолимая пропасть в таких вещах как масштабируемость, доступность, надежность.
Используя инструментарий Azure для R, мы довольно долго можем балансировать на грани между гибкостью R и надежностью + другими бенефитами, которые нам дает Azure ML.
P.S.
Приходите на хакатон (о нем я писал в начале) и попробуйте все это сами, пообщайтесь с экспертами и единомышленниками убейте себе выходные. Я, кстати, также буду там (в жюри).
Кроме того, для тех кому будет мало офлайн общения, приглашаю в теплый ламповый slack-чат, где участники хакатона смогут задавать вопросы, делится с друг другом опытом, а после хакатона рассказать о своем крутом решении и продолжать поддерживать профессиональные связи.
Data Science must win!
Комментариев нет:
Отправить комментарий